


.png) 手机流量卡
手机流量卡 免费领卡
免费领卡 号卡合伙人
号卡合伙人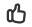 产品服务
产品服务 关于本站
关于本站java中的垃圾回收算法与垃圾回收器
常用的垃圾回收算法
标记-清除
标记清除算法是一种非移动式的回收算法,分为标记 清除 2个阶段,简而言之就是先标记出需要回收的对象,标记完成后再回收掉所有标记的内存对象,如下图
可见回收后图中被标记的对象被删除回收了,但是碎片化比较严重不连续 对于下次分配大对象的时候由于内存不连续性影响比较大,而且每一次Gc的时候需要执行2个操作 1次标记 1次回收
标记-整理压缩
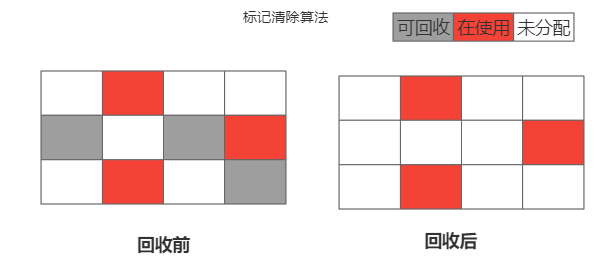
标记整理压缩算法是一种移动式的算法,由于上面标记清除算法导致内存不连续的问题 标记-整理算法就解决了这个问题。
工作原理也是2阶段操作而且更复杂了,首先找出(root)根地址的对象一直寻找标记是否被引用,引用了就标记一下,标记完成后把标记的对象按顺序移动排列在一起并清除掉边界的未标记的对象,这样就没有内存碎片。
缺点
由于标记完成后需要移动对象 移动的过程可能会产生STW
2次+调整指针
复制算法
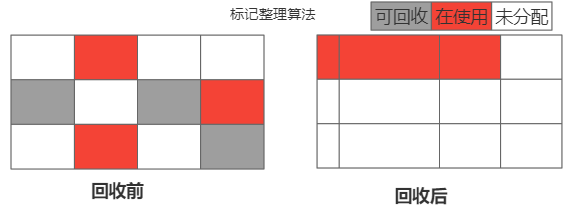
复制算法更粗暴了,逻辑也很简单 通常直接申明了2块一样大小存储空间,每次只使用其中1块空间,当使用的这块空间不够用的时候就触发回收操作,将存活的对象copy到另一块空间中按顺序存放,可回收的就回收删除掉,这样一来就不会出现内存碎片,但是要多浪费50%的内存空间,主要用于年轻代 比如s0 s1亦是如此。
分代回收算法
根据对象的存活周期划分为新生代、老年代。因此可以根据不同年代的特点使用不同的回收算法。分代收集目前是大部分JVM
新生代特点
在新生代中大量的对象产生 又有大量的对象需要销毁,他们存活时间都比较短。基本上都是回收的时候大部分会被回收掉,只有少量的对象是存活不回收的。
存活对象少,垃圾对象多这就比较适合使用复制算法,复制算法需要用到2块内存空间 每次只使用其中一块,在jdk8中不只是单纯的划分为
s0s1二块存储空间,还新增了一块Eden,s0 s1的默认大小是eden的8/1 这样设计的目的在于每次触发回收的时候把90(eden+其中1个s区)的区域中存活的对象copy到10%的存储中,理论上清除了90%的空间,这样做的好处就是不需要花50%的存储空间,只浪费了10%的空间就实现了这个算法逻辑。老年代特点
老年代的特点就是对象存活时间都比较长,大量的存活对象就不适合像新生代一样用复制算法了 因为copy的成本太高,这种就比较适合标记清除算法,或者标记清除整理算法。
优缺点概述
算法名称 优点 缺点 标记-清除 简单 位置不联系 碎片化严重 效率低 2次扫描 标记-压缩整理 没有碎片 效率低 2次扫描 可能会多次重置指针 复制算法 没有碎片 简单高效 浪费空间
垃圾回收器
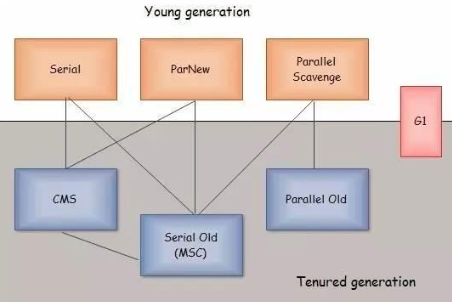
上面的垃圾算法仅仅只是一个理论上的算法 ,正在实现这些算法的叫垃圾回收器,在工作中具体是怎么回收工作的可以不关心,但是需要了解不同的垃圾回收器是基于哪种算法实现的,有助于出现性能问题的时候有思路去参数调优,而不是盲目的问度娘。各个年轻代 老年代垃圾回收器可组合配对方式如下图所示

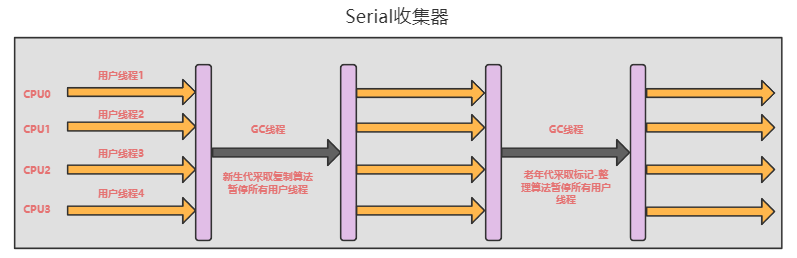
serial串行收集器
serial回收器是一个串行单线程回收器,在进行垃圾回收的时候必须暂停用户工作线程,直到回收线程处理完成,每次回收必然会STW。比较适合跑在client端应用
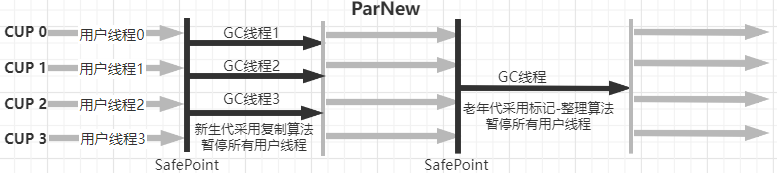
ParNew收集器
ParNew回收器是新生代垃圾回收器, 就是serial的多线程版本 其它基本上serial差不多的,在ps回收器没有出来之前parNew+cms是服务器端首选
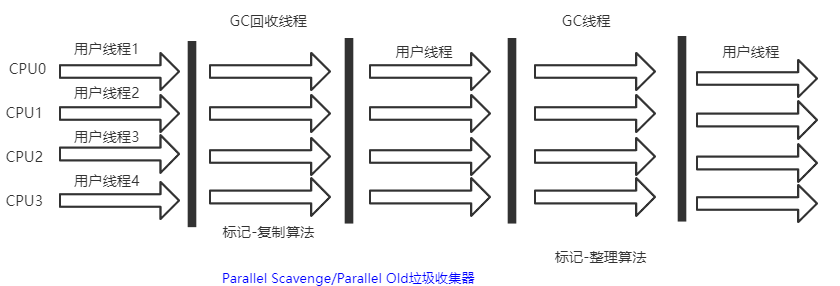
Parallel Scavenge收集器
常说的ps 收集器就算它,ps是一个新生代收集器采用复制算法,多线程并行收集。是jdk8的默认新生代回收器。
看起来和parNew有点一样 反正性能就是比它要强,在应用吞吐量方面更优秀。ps一般是和Parallel Old配合使用
Serial Old收集器
Serial Old收集器是Serial的老年代版本,同样它也是单线程收集,基于标记-整理算法,工作原理可以参考serial。
Parallel Old收集器
parallel old收集器是ps的老年代版本 是多线程收集器 基于标记-整理算法 弥补了serial old单线程的不足,工作原理参考ps收集器工作流程图。ps+po是jdk8默认的组合 也是我在项目中实践最多的组合。
CMS收集器
cms从jdk1.4开始引入,算是里程碑GC产品,开启了Java领域并发(注意并发与并行parallel的区别 并发是值回收垃圾的时候和用户线程一起干活,并行是指多个GC线程同时回收 )回收的方案。是一个优秀的老年代垃圾回收器。
cms从名字就能看出来是基于并发的 标记-清除算法实现的回收器,它的回收流程分为 初始标记-并发标记-重新标记-并发清除 4个阶段。
初始标记 (initial mark)
只是标记GC Root 根对象 会stw 但是由于只是标记了gc roots 所有很快并发标记
根据第1阶段的结果继续往下标记 这个阶段是并发的 不影响用户线程重新标记
为什么会有重新标记这个阶段?是因为并发标记的时候 由于用户线程还在运行 可能产生了新的垃圾 所以需要在标记一次,当然由于第2阶段标记过一次了,这一次理论上会很快 这个阶段会STW并发清除
清理需要回收的对象 不影响用户线程使用。cms有个开关(-XX:CMSFullGCsBeforeCompaction=0)默认是开启碎片整理,由于cms清理后的空间也是有碎片存在的,所以一次清理就会整理一次碎片。此阶段用户线程同样会产生新的垃圾 目前没有解决清除 网上叫为浮动垃圾。
所以cms只有在并发标记和并发清除阶段是不影响用户线程停顿的。初始标记 和 重新标记 也是划分的区域标记的,总体上能跟控制gc停顿时间 提高用户体验,工作原理如下

当老年代内存使用到92%(-XX:CMSInitiatingOccupancyFraction=92)之后出触发cms回收一次,如果cms在回收期间中 剩余的内存不够用户工作线程使用了(报异常Concurrent Mode Fail) 那么serial old回收器就成了紧急替补队员立即进行回收一次,当然停顿的时间就更长了。由于cms部分阶段是用户线程和gc线程一起工作,如果启动阈值设置得太高,容易导致用户工作线程不够用触发cmf异常,性能反而降低。
G1收集器
G1垃圾回收器可以同时支持年轻代、老年代,G1并没有在物理分区隔离,上面的提到的垃圾回收器都是物理上进行分区的,G1是由一块一块大小相同的region组成,虽然没有物理上进行分区,但是依然保留了年轻代 老年代的概念。回收流程有点类似cms。也是分为初始标记、并发标记、最终标记、筛选回收 4个阶段。
Region的大小可以通过G1HeapRegionSize参数进行设置,其必须是2的幂,范围允许为1Mb到32Mb。基于堆内存的初始值和最大值的平均数计算分区的尺寸,平均的堆尺寸会分出约2000个Region。分区大小一旦设置,则启动之后不会再变化。region之间采用复制算法,因此不容易产生内存碎片。每个Region都有一个Remembered Set。当对引用进行写操作的时候,G1检查该引用的对象是否在别的region中,是的话,则通过CardTable把相关引用信息存到被引用对象的Remembered Set中。当进行内存回收时,把RememberSet加入到GC Roots根节点的枚举范围。这样就可以保证不全堆扫描也不会有遗漏。 内存结构如下

Survivor regions(年轻代-Survivor区)
Old regions(老年代)
Humongous regions(巨型对象区域) 占用了Region容量的50%以上对象 巨型对象比较大 一般在并发标记阶段如果可以回收就直接回收了。
Free resgions(未分配区域,也会叫做可用分区)-上图中空白的区域
G1之所以这里厉害在于它用到了一些数据结构的技巧
TLAB(Thread Local Allocation Buffer)本地线程缓冲区
PLAB(Promotion Local Allocation Buffer) 晋升本地分配缓冲区
Collecion Sets(CSets)待收集集合
Card Table 卡表
Remembered Sets(RSets)已记忆集合
回收流程大致如下
初始标记
只是标记GC Roots根对象 会stw
并发标记
从上一步标记的GC Roots开始计算可达性分析并标记 这阶段耗时但是是并发的 不影响用户线程使用
最终标记
上一步执行的过程中产出的变动再一次计算和标记 会stw 短暂的停顿,JVM将这段时间对象变化记录到Remembered Set Log中,在最终标记阶段把Remembered Set Log合并到Remembered Set中。筛选回收
为什么多了一步筛选再回收,在于G1在收集的时候会优先回收比较有价值的region区域,垃圾对象比较多 存活对象比较少的region就算是有价值的 这样就能有效的提高回收效率。因为优先回收掉有价值的region而不是一下全部把堆中的全部垃圾回收完,所以回收的时间基本上能够把控。这个阶段是并行操作但是会有短暂的STW基本感知不到。
JDK10 之前的G1中的GC只有YoungGC,MixedGC。FullGC处理会交给单线程的Serial Old垃圾收集器。
zgc收集器
Shenandoah
本文链接:https://www.kkkliao.cn/?id=153 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。





